

Data Quality in Automation: The Hidden Key to ROI (2026)
Automation is a multiplier. If you automate a good process, you get efficiency. If you automate a bad process, you get chaos only faster. This fundamental truth brings us to the concept of data quality in automation. In 2026, as companies race to adopt AI and high-speed workflows, the cleanliness of the data flowing through these pipes has become the single biggest determinant of success.
It is the “silent killer” of ROI. You can buy the most expensive software, but if your input data is messy, incomplete, or duplicated, your dashboard will lie to you. This guide explores why prioritizing data quality in automation is not just an IT task it is a strategic imperative for finance leaders who want to trust their numbers.
Table of Contents
- 1. The High Cost of Bad Data
- 2. The 6 Dimensions of Data Quality
- 3. Why Automation Amplifies Errors (The Velocity Trap)
- 4. Automated Validation Techniques
- 5. The “Human-in-the-Loop” Safeguard
- 6. Building a Clean Data Pipeline
- 7. Tools for Data Hygiene
Impact: Good vs. Bad Data
| Scenario | Action | Result |
|---|---|---|
| Poor Quality | Automated invoice payment | Paying duplicate invoices or wrong amounts. |
| High Quality | Automated reconciliation | Books close in hours, not days. |
| Poor Quality | AI Analytics | “Hallucinated” forecasts leading to bad strategy. |
1. The High Cost of Bad Data
Before fixing the problem, we must quantify it. Failing to maintain data quality in automation is expensive. According to Gartner, poor data quality costs organizations an average of $12.9 million every year. This isn’t just lost revenue; it is the cost of rework, compliance fines, and damaged reputation.
For a finance team, “bad data” looks like this: A vendor name spelled “TechCorp” in one invoice and “Tech Corp Inc.” in another. Without standardization, your system treats them as two different entities, messing up your spend analysis.
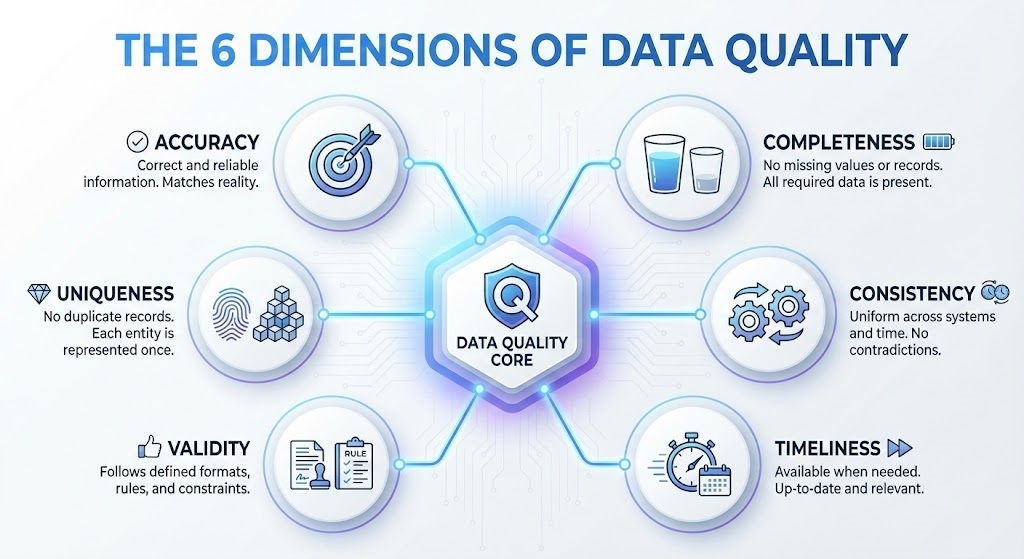
2. The 6 Dimensions of Data Quality
To master data quality in automation, you need a framework. Data professionals typically measure quality across six core dimensions (often cited in ISO 8000 standards):
- Accuracy: Does the data reflect reality? (e.g., Is the extracted tax amount correct?)
- Completeness: Are all required fields present? (e.g., Missing PO number).
- Consistency: Is the data the same across all systems?
- Timeliness: Is the data available when needed?
- Validity: Does it follow the correct format? (e.g., Dates as YYYY-MM-DD).
- Uniqueness: Are there duplicates?
Using an extraction tool like ParserData helps enforce these dimensions by structuring unstructured PDFs into validated JSON output.
3. Why Automation Amplifies Errors (The Velocity Trap)
There is a dangerous misconception that automation “fixes” data. It does not. It accelerates the flow of data. If you implement a high-speed business document automation workflow without quality checks, you create the “Velocity Trap.”
Imagine sending 1,000 incorrect invoices to your ERP in 30 seconds. The time you saved on data entry is now spent on a forensic accounting nightmare to clean up the mess. This illustrates why data quality in automation must be a “gatekeeper” step, not an afterthought.
4. Automated Validation Techniques
How do we ensure high quality without slowing down? By using automated validation rules. Modern pipelines use logic to “sanitize” data in flight.
- Format Validation: Using Regex to ensure emails have an “@” and phone numbers have 10 digits.
- Reference Data Checks: Checking if the extracted “Vendor ID” actually exists in your database.
- Mathematical Cross-Checks: Ensuring that (Net Amount + Tax) equals the Total Amount.
Pro Tip: Implement “Hard” and “Soft” stops. A “Hard Stop” blocks data with critical errors (missing Bank IBAN). A “Soft Stop” flags data for review but allows processing (e.g., missing zip code).
5. The “Human-in-the-Loop” Safeguard
Total autonomy is a myth for complex data. The gold standard for maintaining data quality in automation is the Human-in-the-Loop (HITL) model. As discussed in our automation best practices guide, you should set a “Confidence Threshold“.
If the AI is 99% confident it read the invoice correctly, it passes. If it’s only 70% confident (maybe the scan is blurry), the system pauses and asks a human to verify just that specific field. This hybrid approach guarantees 100% data integrity.

6. Building a Clean Data Pipeline
To implement rigorous data quality in automation, you need to design your pipeline with hygiene in mind. Here is a 4-step architecture:
- Ingest: Receive raw documents (PDF, Email).
- Standardize: Use AI to convert diverse formats into a single standard (e.g., all dates become ISO 8601).
- Validate: Run automated logic checks (Math, Lookups).
- Load: Only clean, validated data enters your ERP.
MIT Sloan Management Review emphasizes that this “data supply chain” mindset is what separates digital leaders from laggards.
7. Tools for Data Hygiene
You need a tech stack that supports these principles. ParserData is built specifically to handle the “Ingest and Standardize” steps, turning messy PDFs into structured JSON.
For the “Validate” step, connecting ParserData to a platform like n8n allows you to build complex logic rules without coding. We have a template that demonstrates a validation workflow in action.
🚀 Download Validated Data Workflow Template
Pro Tip: Don’t just monitor the data; monitor the “Data Drift”. If your system suddenly starts flagging 50% of invoices as errors, your validation rules might be outdated, or a vendor might have changed their layout.
Conclusion
Ensuring data quality in automation is not a one-time fix; it is a continuous discipline. By filtering out the noise and ensuring only pristine data enters your systems, you build a foundation of trust. Trust allows you to automate more aggressively, scale faster, and make decisions with absolute confidence.
Don’t let bad data derail your digital transformation. Start with clean inputs using ParserData and watch your efficiency soar.
Frequently Asked Questions
What is the “Garbage In, Garbage Out” principle in automation?
It means that if you feed poor quality data into an automated system, the output will also be poor—but it will be produced much faster. Automation amplifies the impact of bad data errors.
How do you measure data quality in automation?
You measure it using six key dimensions: Accuracy, Completeness, Consistency, Timeliness, Validity, and Uniqueness. Each dimension can be tracked with specific KPIs (e.g., % of invoices missing VAT numbers).
Can AI fix bad data automatically?
To an extent, yes. AI tools like ParserData can “repair” common errors (like standardizing date formats) during extraction, but logical errors (like a wrong vendor address) typically require human validation.
Why is data consistency important for finance?
Consistency ensures that data across systems speaks the same language. For example, ensuring “Q1 2026” in an invoice matches the “First Quarter” period in your ERP is vital for accurate financial reporting.
What tools help improve data quality?
Tools that combine IDP (Intelligent Document Processing) with validation logic are best. ParserData extracts data, while integration platforms like n8n can run cross-checks against your database before final storage.
Recommended
- Why Automate Data Processing? 5 Strategic Reasons
- How to Automate Data Extraction: 5 Step Guide
- What Is Data Extraction? The Complete Guide
- Explaining PDF Data Extraction: Technical Guide
Disclaimer: All comparisons in this article are based on publicly available information and our own product research as of the date of publication. Features, pricing, and capabilities may change over time.





